
Recently Power Apps made the headlines in a way that Microsoft would have liked to avoid at all cost:
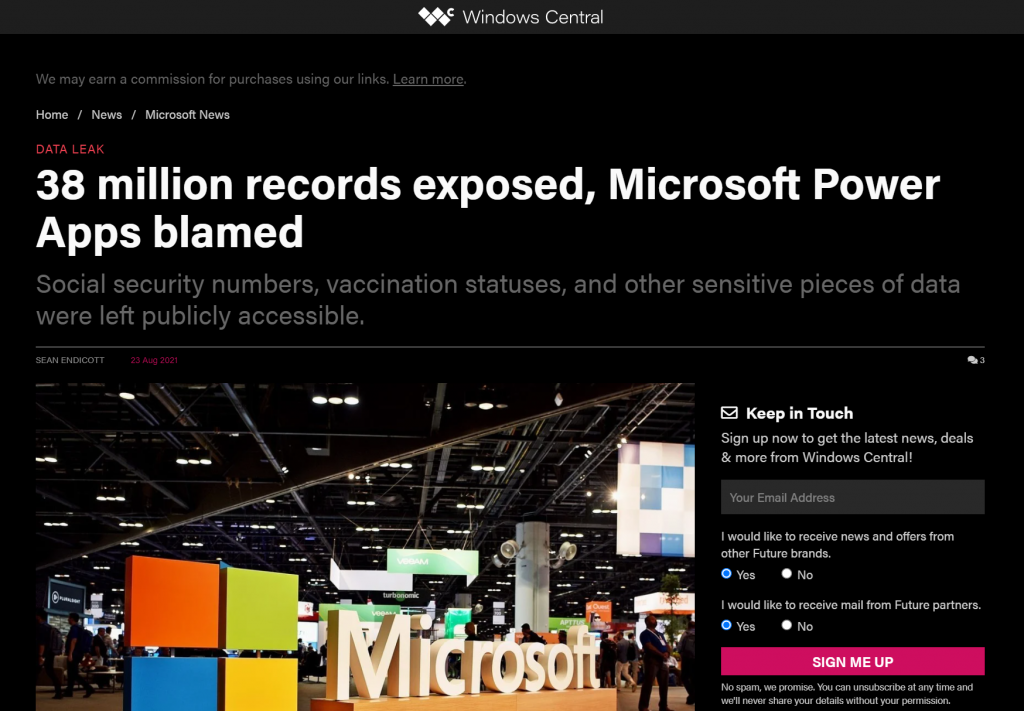
The news headlines today aren’t exactly the most neutral source of information, but luckily we also have access to the full report from the security research team at UpGuard. Here’s what happened according to them:
The UpGuard Research team can now disclose multiple data leaks resulting from Microsoft Power Apps portals configured to allow public access – a new vector of data exposure. The types of data varied between portals, including personal information used for COVID-19 contact tracing, COVID-19 vaccination appointments, social security numbers for job applicants, employee IDs, and millions of names and email addresses.
UpGuard
Sounds serious, and it certainly shouldn’t be sweapt under the rug by anyone working with Microsoft Power Platform. We have a lot to learn from an incident like this and the concerns it may bring up along with it. As these low-code technologies become more widely used across different industries, not all publicity will be positive.
There have of course been some concerns raised by IT practitioners already before this Portals incident on what’s the general impact that low-code platforms will have on business solutions development. How to secure customer data and to build proper governance practices around these tools is a topic that is often covered when talking about Power Platform with customers.
I personally already used the above headline as an example in a governance workshop with a customer on the very next day after the report was published. The discussion was quite neutral and it served well in acknowledging both the important role that Power Platform tools can have in business processes, as well as the need for practices that allow them to be safely used in developing new solutions.
The other alternative where such a topic would not be proactively addressed in a transparent manner could instead lead to more controversial reactions down the road. Some people may have negative experiences in their past that might lead to seeing these new events as an enforcement of their existing beliefs.
It’s hard to prevent people from drawing the wrong conclusions based on incomplete information if we don’t bring all the relevant pieces into light. To help in such examination of the evidence, in this blog post I’ll present some fictitious statements that could potentially be made based on reading the news headlines. Then I’ll offer my own perspective on whether they would be justified or not.
“Bugs in Microsoft’s software caused the data leak!”
This wasn’t an actual bug, rather an unfortunate feature. As the report title from UpGuard hints, it was “by design” when examined from a technical perspective. Also, that was the initial response from Microsoft’s side, as shown in the report:
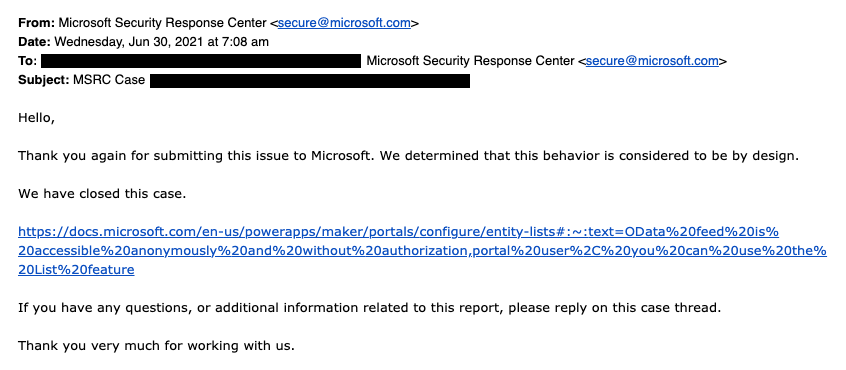
The above response is in my opinion the biggest mistake from Microsoft in this whole incident. Being tone deaf when presented with something that had already proven to be a pattern leading to unintended disclosure of confidential customer data via numerous Power Apps Portals out there is… Well, it’s what happens in large corporations, unfortunately.
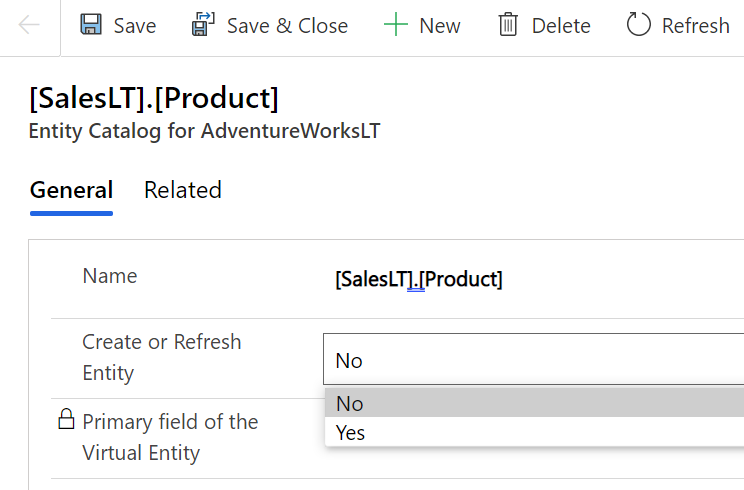
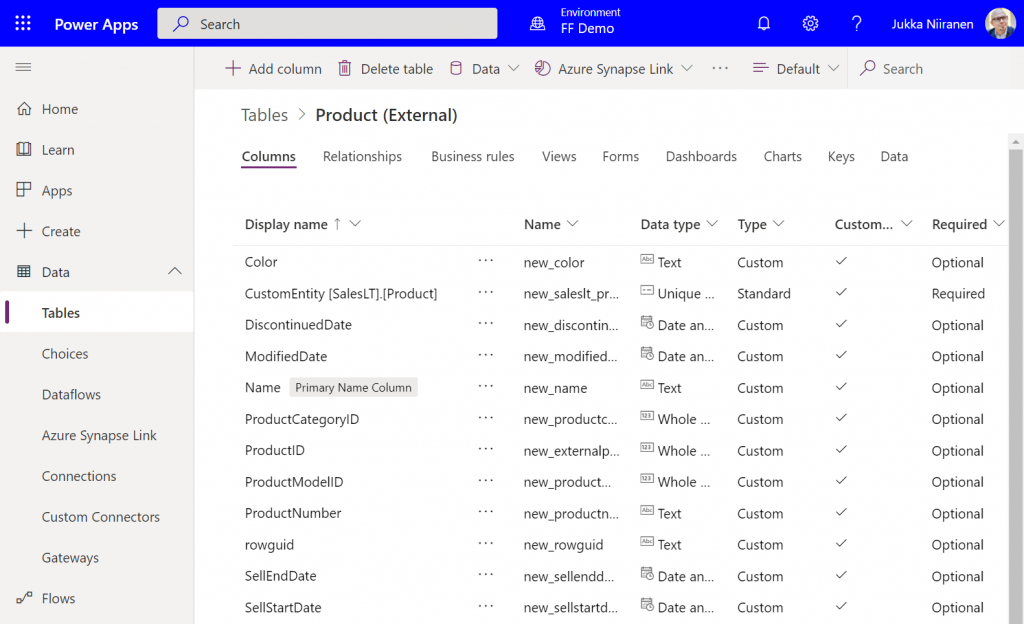
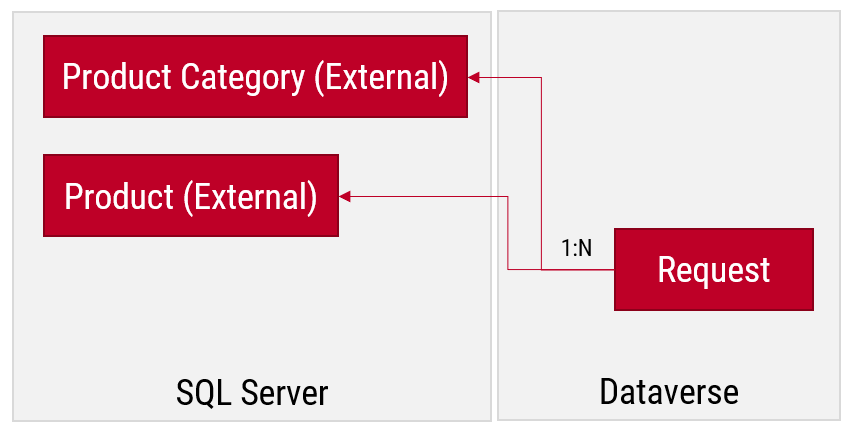
What was this “by design” feature then? In the state that the Portals configuration experience was at the time of the investigation, there wasn’t any strong push from the product side to make the data tables used in the portal as private. It was a neutral platform built specifically to take records from your organization’s internal Dataverse tables into a public website, then giving you the choice to either show all the contents to anyone, or limit the visibility through a very granular security model to only a small subset of records.
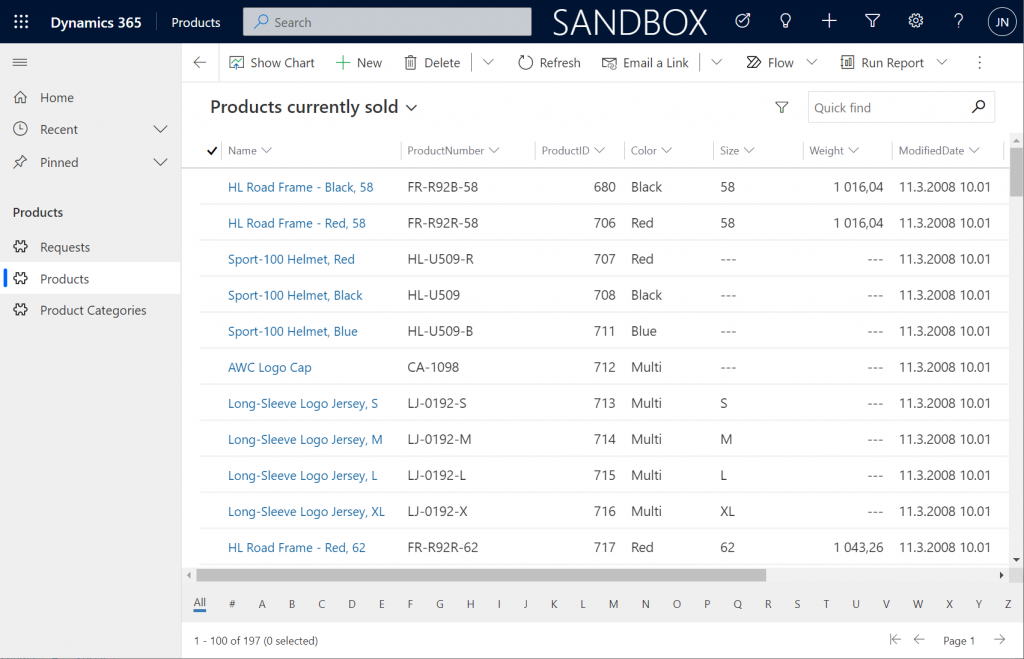
As an example: you could show all the available locations where COVID-19 vaccinations were being offered (public table). Then you’d give the logged in user the ability to create an appointment record (private table with access control). Both are an integral part of the business process managed via a portal, yet the rules for showing them to the website visitors are directly opposite. The technical platform has to cater to both these requirements.
As it happened, there was a way through which the portal developer could forget to enable the table permissions that the private data should have in all areas where it was used. Now, the reason why this mistake wasn’t immediately obvious was that the Power Apps Portal product included a feature that allowed publishing this data as OData feeds. These would not be visible in the website pages necessarily, but they were technically available as long as you knew the right path from where to search for them.
In our example, a public OData feed of locations could have been useful for integration purposes. For reservations made by private individuals, an unauthenticated feed would never be a good idea. Yet the platform didn’t know what the developer wanted.
After this incident was reported by UpGuard, Microsoft changed the defaults and made it require more conscious effort to publish the feeds for unauthenticated consumption.
“Poor default settings in the Portal product were dangerous!”
There’s no denying that discovering more than a thousand Power Apps Portals misconfigured to expose confidential data to unauthenticated users is a big number. Yet the total number of Portals out there is… well, let’s just say it’s certainly multiple times that.
As part of their research, UpGuard enumerated through the various available powerappsportals.com and microsoftcrmportals.com subdomains to programmatically scan the sites with potential unintended OData feeds published. Many were found through this method, but still this problem affected only a small subset of all Portals websites out there.
The majority of Portals developers will have been aware of the setting that must be enabled for any data that you don’t want to be publicly available on your website. Nick Doelman explains the “Enable Table Permissions” setting very clearly in his excellent blog post. It’s not really fair to claim that this would have been impossible to notice while building your Portal app:
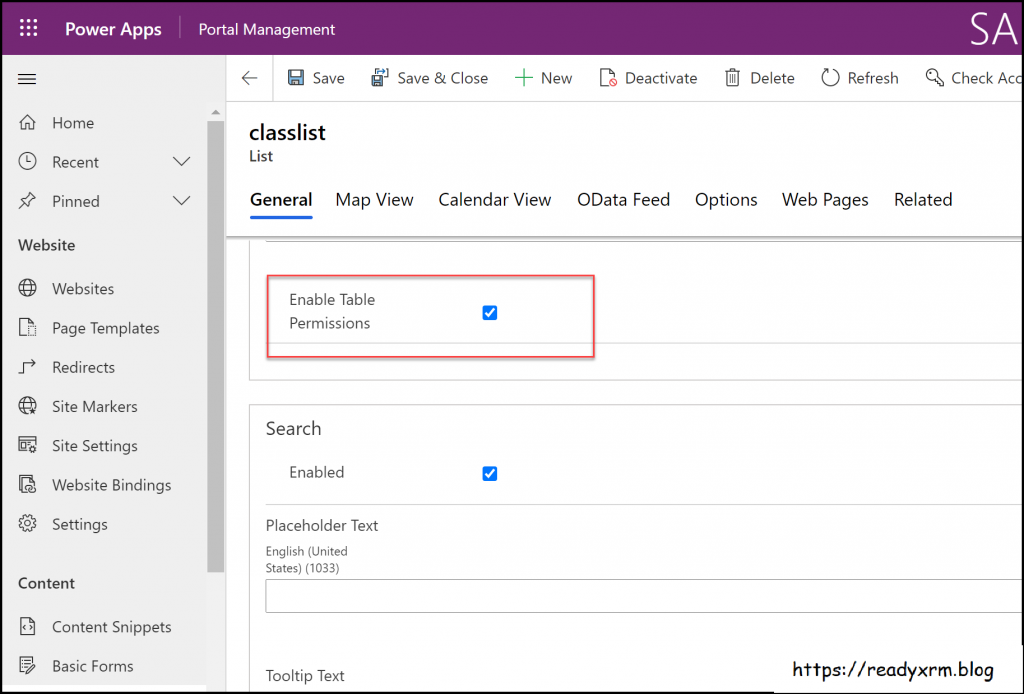
If it has been news to you and you have built websites with Power Platform tools, then I seriously recommend you to take advantage of this generous offer by Nick and enroll for his Power Apps portals Security Deep Dive course:
Update 2021-08-31: you should also check this video from George Doubinski about the Portals behaviour before & after the default setting change:
“Microsoft should prevent such things from happening on their cloud service!”
Power Platform is a suite of low-code tools that allows you to build your own apps. Whatever business logic the published app contains is ultimately the responsibility of the app creator. Same goes for the data you manage with that app. Technology providers can’t easily stop people from building unfit solutions with their products.
There’s a great analogy in George Doubinski’s blog post “How to secure Power Apps portal from making the news” that I’ll repeat here. If you’re a company selling nail guns and a few unfortunate customers of yours shoot themselves in the foot – what should you do about it? Sure, your product probably came with all kinds of instruction manuals and warning signs that try to explain the importance of learning how to use such power tools. Similar to how Microsoft now shows a banner saying “table permissions should be enabled for this record or anyone on the internet can view the data”, to try and warn people not to hurt themselves.

Let’s look at an example from another area of Power Platform that I cover frequently in my blog: licensing. Any customer could easily use this platform to build an automation that is a clear violation of the multiplexing rules of the very same platform’s licensing terms. Just create a Power Automate cloud flow that automatically pushes all new opportunities from your Dynamics 365 Enterprise Sales app into a SharePoint list accessible to your whole organization with no Dynamics licenses assigned to them. Congratulations, you’ve again used the powerful tool to hurt yourself in a way that the vendor couldn’t have stopped.
“I knew citizen developers couldn’t be trusted to build real business applications. So much for low-code!”
Did you look at the types of customers that suffered from this data leak? If not, I’ll list some of them from the UpGuard report here, to give perspective:
- American Airlines
- Ford
- State of Indiana
- New York City Municipal Transportation Authority
- Microsoft
These don’t sound exactly like the kind of organizations where a lone citizen developer who discovered a neat tool in his Office 365 app launcher just went ahead and built a portal on top of millions of rows of contact records and other sensitive data. If I had to guess, I’d assume there has been a proper development team working on many such customer facing services – not just citizens.
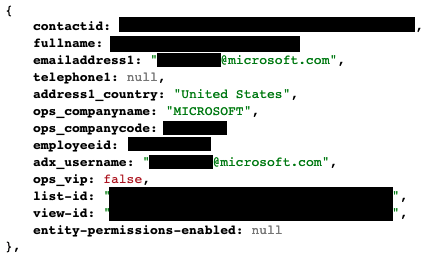
The above picture is an example from the report’s contents that was captured via the unsecured OData feeds. It is from the Global Payroll Services Portal for Microsoft employees, built (presumably) by professionals working with software. Despite of all the resources and knowledge behind these, the misconfiguration of a Power Apps Portal still went into production sites.
Although not directly related to this incident, on the very same week there was also another unfortunate data leak reported concerning the Microsoft cloud. Only this time it was around CosmosDB and the database primary keys that got leaked, exposing private data from thousands of Azure customer organizations. The misconfiguration seems to have been carried out by Microsoft software developers while they were integrating Jupyter Notebooks with CosmosDB to provide a new platform feature to customers.
Regardless of whether you are clicking through low-code configuration pages or writing your own lines of custom code, mistakes can happen.
“Suites like Power Platform are becoming way too complex for anyone to keep track of all these features & settings that can cause harm!”
This is certainly true in the sense that a single person will not have an A-to-Z understanding of Power Apps in Canvas/Model-driven/Portals flavor, Power Automate in the cloud and on the desktop, Power Virtual Agent, Dataverse, AI Builder, Power BI and its data platform back-end… It’s way too much for anyone to consume as documentation, let alone master in practice.
We should be asking where the assumption actually comes from that an app maker or developer should have end-to-end knowledge of the whole Microsoft low-code stack? Whether you’re a customer or a partner, it’s very important for you to not be blinded by all the flashy product demos and testimonials on “how company X digitally transformed themselves, using software suite ABC”. It doesn’t all happen thanks to this one mythical app hero who can take on any challenge – rather it’s the result of the right person finding the right tool to solve one specific problem at a time. Repeatedly, at scale.
Low-code is a team sport and you will increasingly see the fusion development approach be promoted by Microsoft. This emphasizes the fact that an optimal mix of business domain expertise and technical software development skills is a better approach to achieving long term business value with low-code than relying on lone superheroes to do it all. In the end, just because you’re not writing as much code as earlier doesn’t mean the resulting systems would be simple:
Low-code tools may be easy to approach, but the solutions you create with them can be as complex to manage as custom software.
The data leak was the result of a feature built into the platform that the persons developing the customer specific solution were not aware of. They didn’t purposefully create the OData feeds, rather the software product generated them based on the underlying logic of how it was meant to streamline certain app development tasks. The best chances for having awareness of all these moving parts in the end solution is to ensure people have a realistic opportunity to focus on their primary tools and continuously sharpen their skills.
“This incident proves you need product X / service Y from partner Z to be safe with Power Platform!”
Events like these are bound to inspire companies working in the Microsoft ecosystem to try and gain exposure of their own by riding on the news wave. It never hurts to sprinkle a little FUD tactics on top of your marketing message, right?
Now, I have to be transparent and admit right away that we are in the business where the questions and concerns coming from Microsoft customers are addressed via our advisory services. Even though we educate organizations on governance best practices and have delivered a few Power Apps Portals solutions to them, I would not make any statements like “buy from us and you’ll never have these kind of problems”. There’s two reasons for this:
- Our aim is to help customers take ownership of their digital tools, not to be the ones who build everything for them & maintain it. New app makers will make mistakes as they learn & grow, they just need a safe space for this (read: not a public website).
- I know how hard it would be to build a technical solution to audit every little detail that could go wrong in the various use cases where Power Platform is be used.
Let’s examine the details of this particular data leak. First of all, to have any technical level protection, you would need a service that can tap into Power Apps Portals specifically. Running something that monitors only Canvas Apps or Model-driven Apps won’t help you here. Even the Power Platform Center of Excellence (CoE) Starter Kit from Microsoft only has the Portals data inventory as a backlog item as of now. If no public APIs are available to tap into a Microsoft cloud service, then you’re unlikely to find any software to do the required tricks for you.
Even if we’d have the same level of telemetry data access as Canvas Apps do, what’s the likelihood of the specific setting in question (Enable Table Permissions) to be exposed and monitored? Well, it is data stored inside Dataverse tables and could be queried via Advanced Find as showed by Nick, so in retrospect we could technically have audit tools built for it. But why would someone built such a third-party product when Microsoft already offers Portal Checker to all customers?
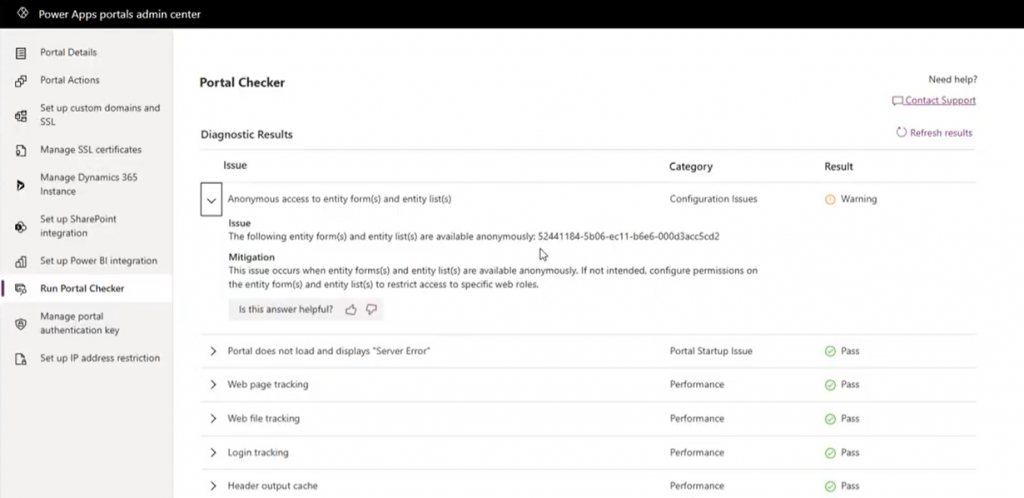
So, there’s unlikely to be an easy & all encompassing solution out there that would address all your Power Platform security and governance concerns. I could even bet that some of the Portals websites that suffered from the OData leak will have been reviewed by security professionals from outside the Microsoft ecosystem and still the issue was not discovered. Probably because they didn’t know where to look.
Because it’s an ever evolving cloud platform, it was possible for Microsoft to quickly react to the incident via a change in their original design, as well as by notifying the customers potentially affected by it. Today the risk of unintentional data exposure is technically lower and the public awareness of such possible misconfiguration among the Power Platform app maker community is much higher.
Yet we have no way to guarantee what will happen tomorrow. Something similar may be discovered in a different part of the platform that will again require attention and action. I think all we can really do is to keep our eyes open and be ready to learn from the new discoveries shared by the network around us.

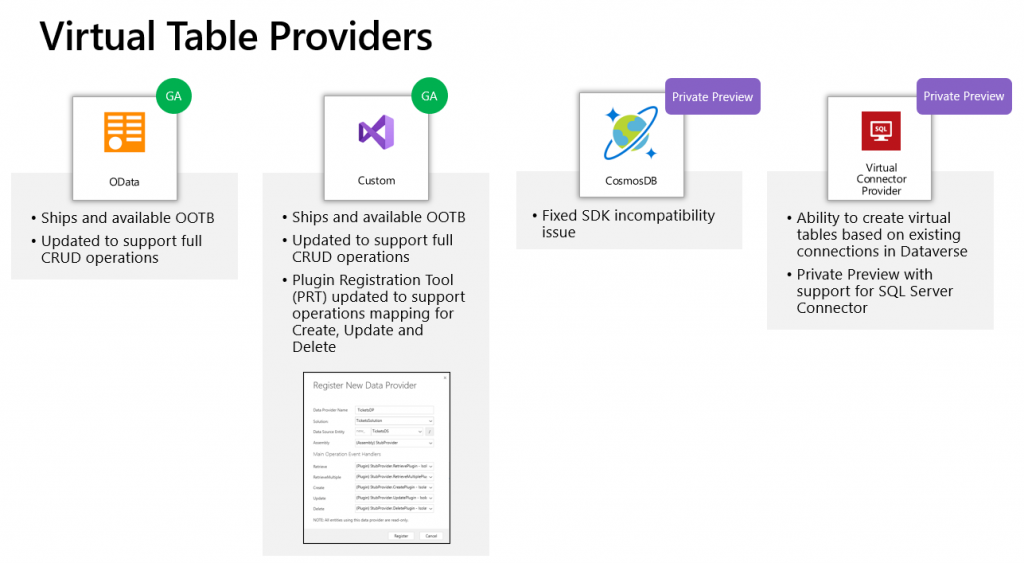

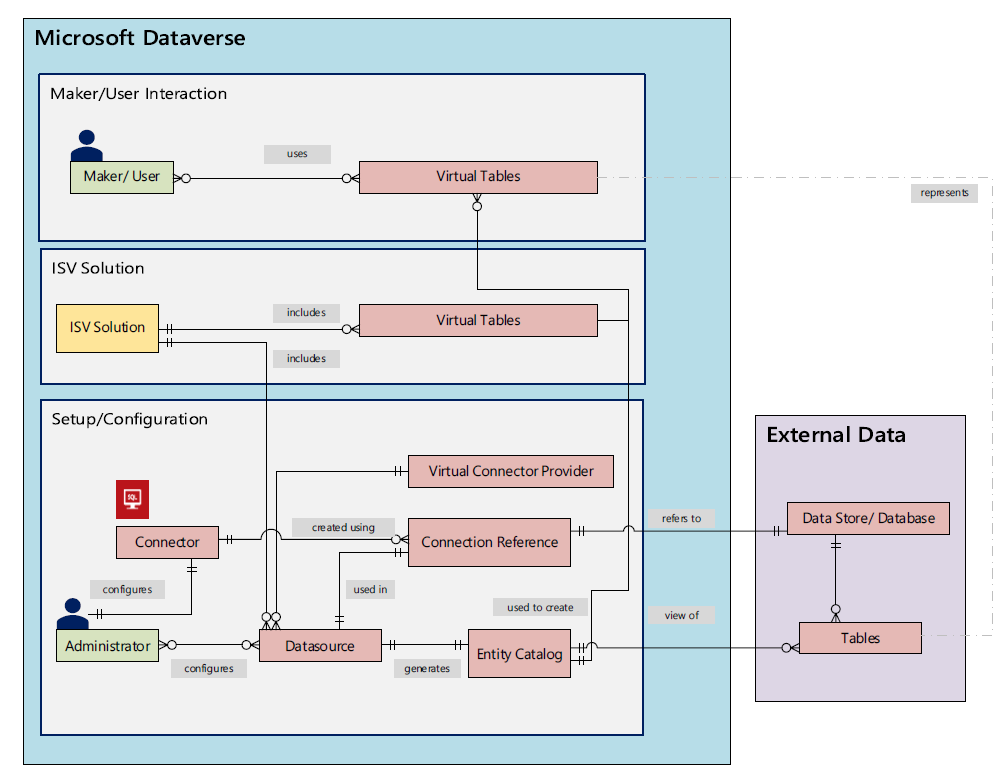
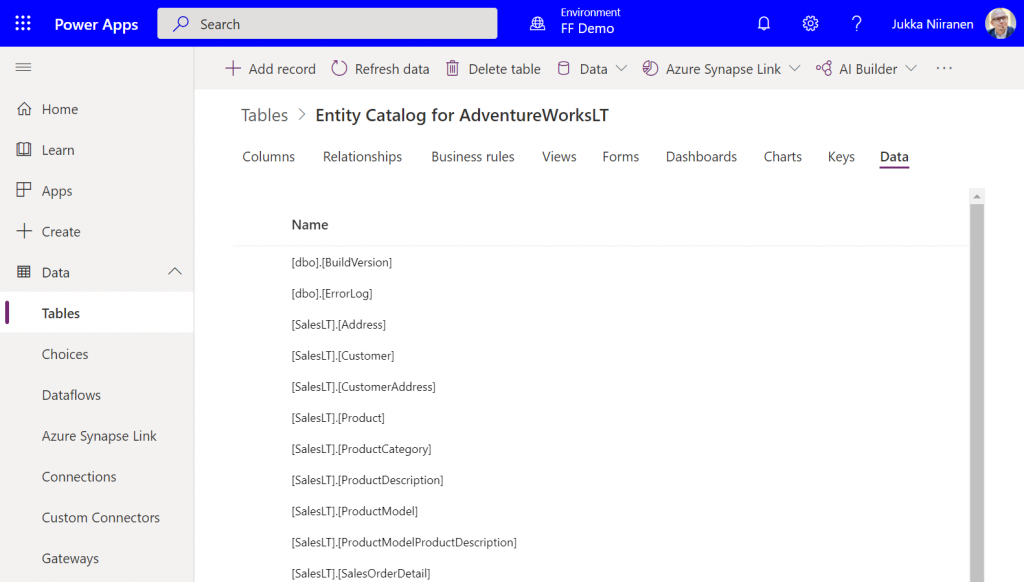
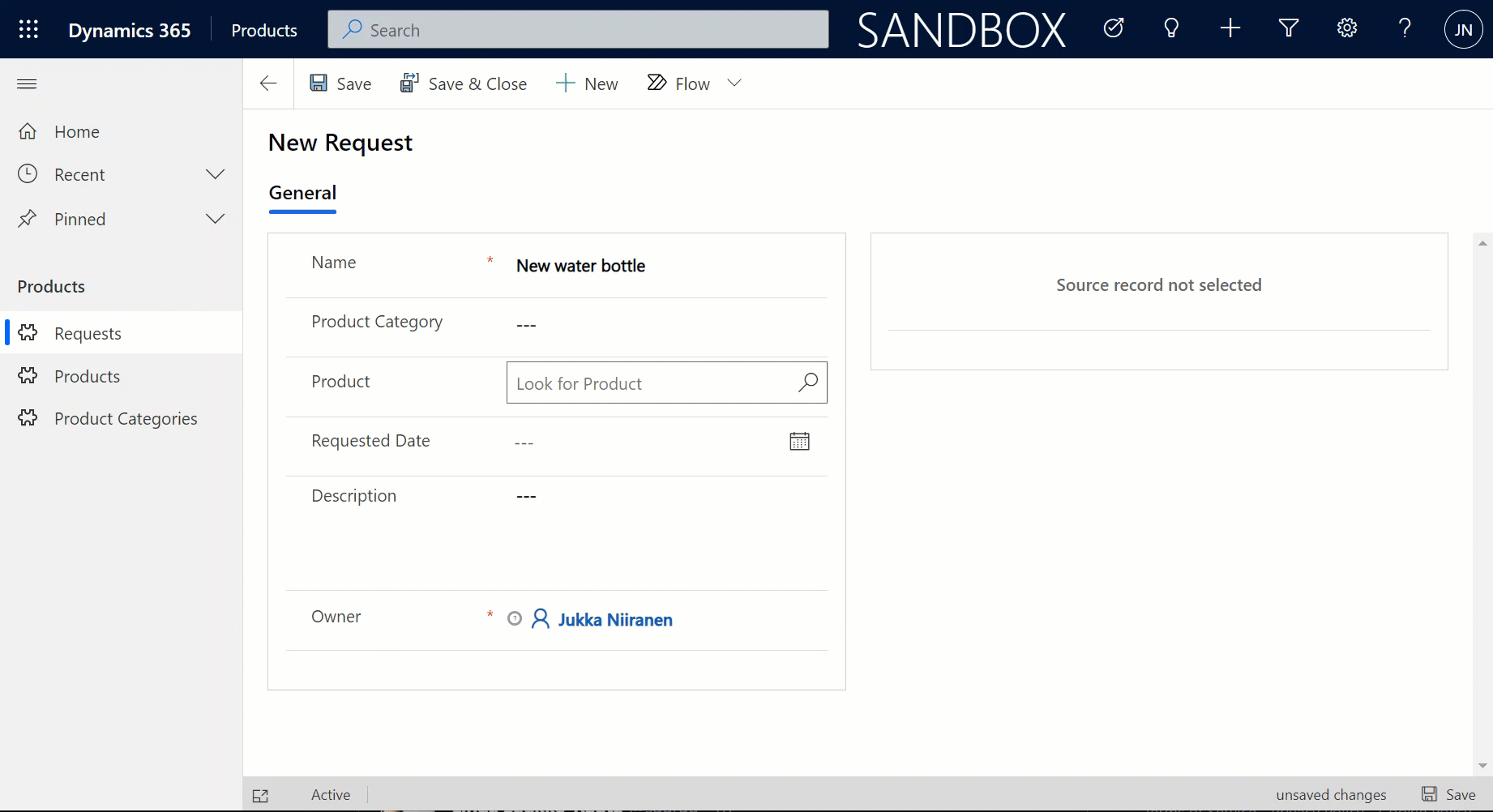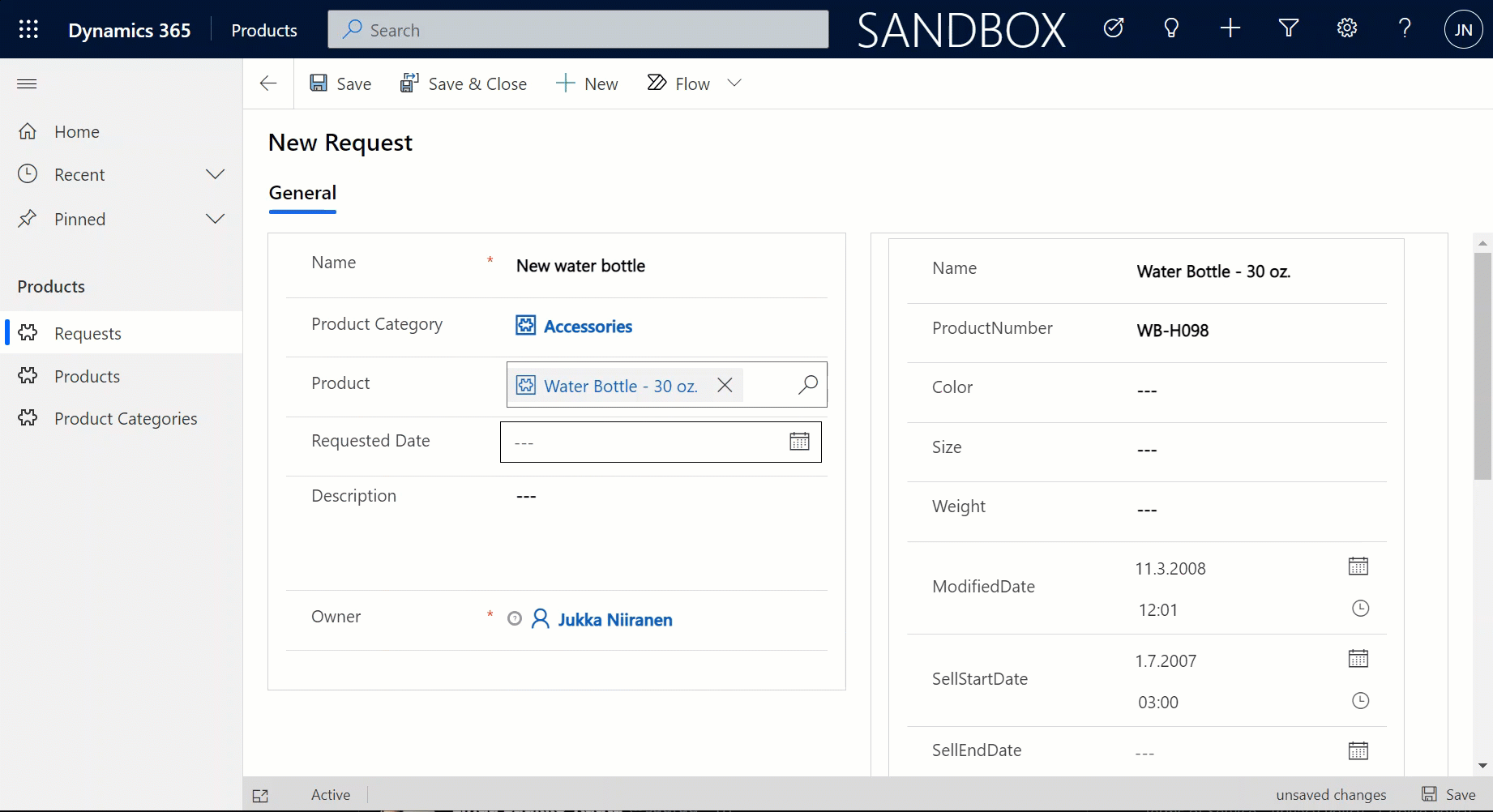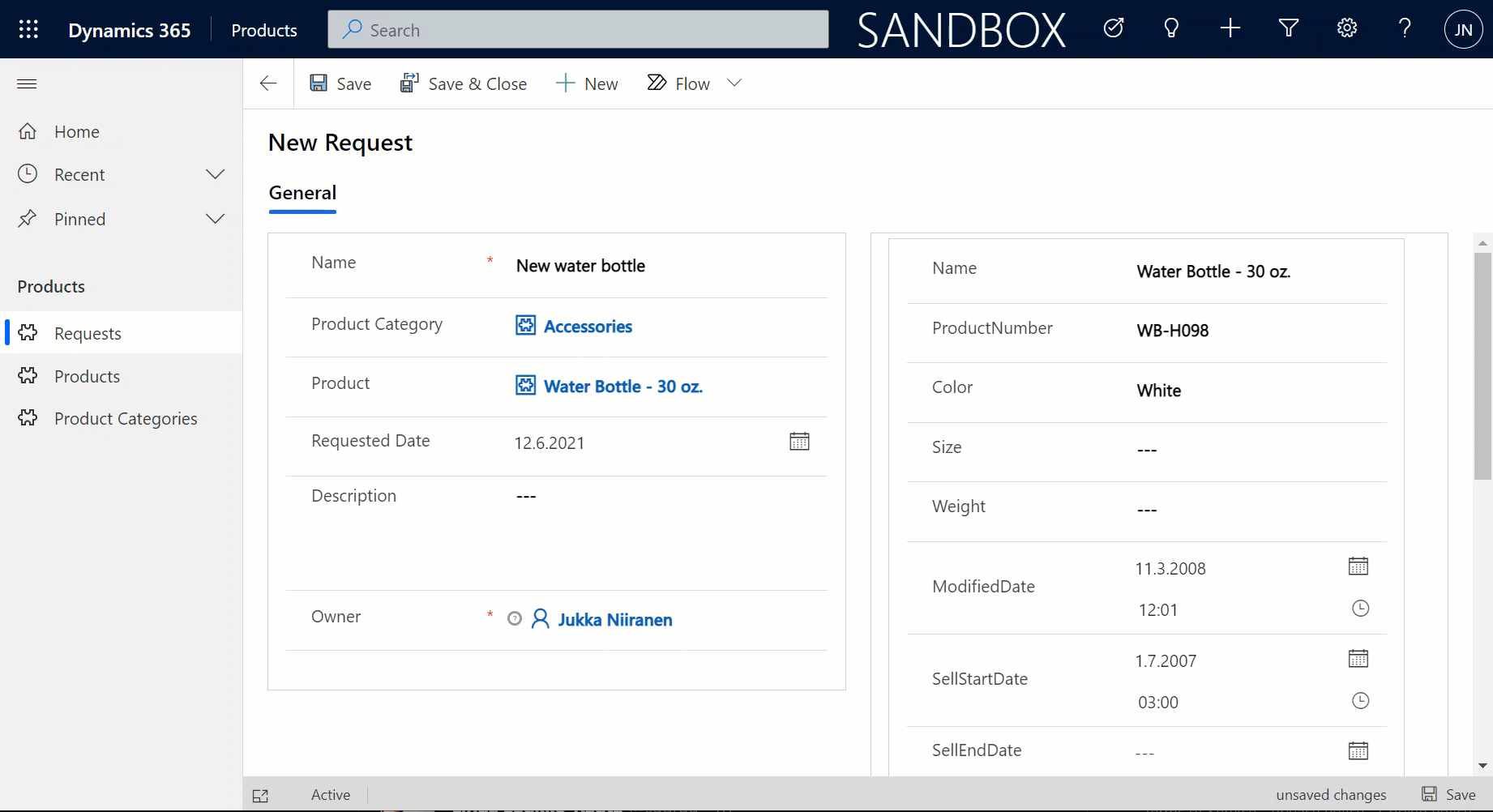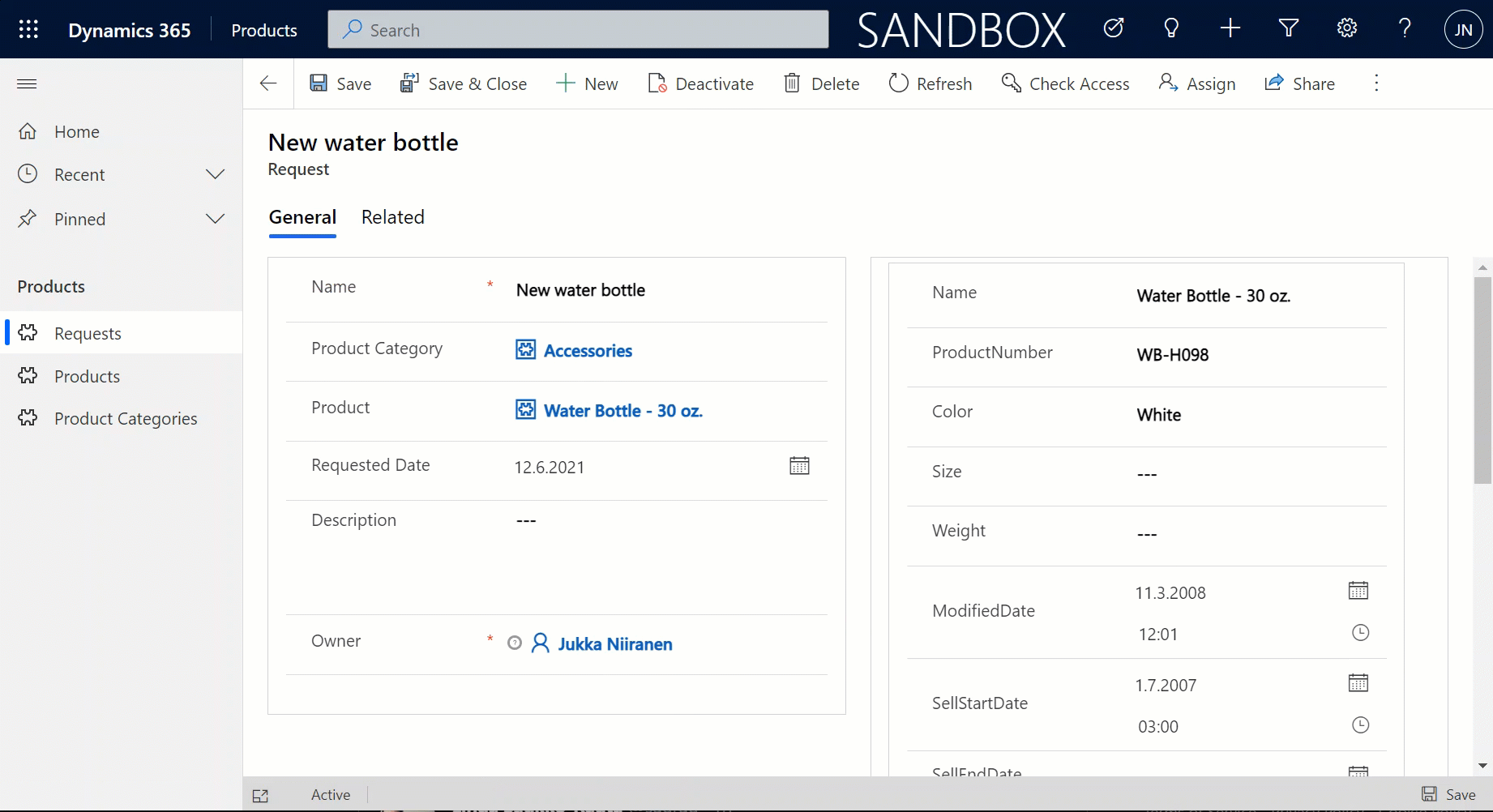
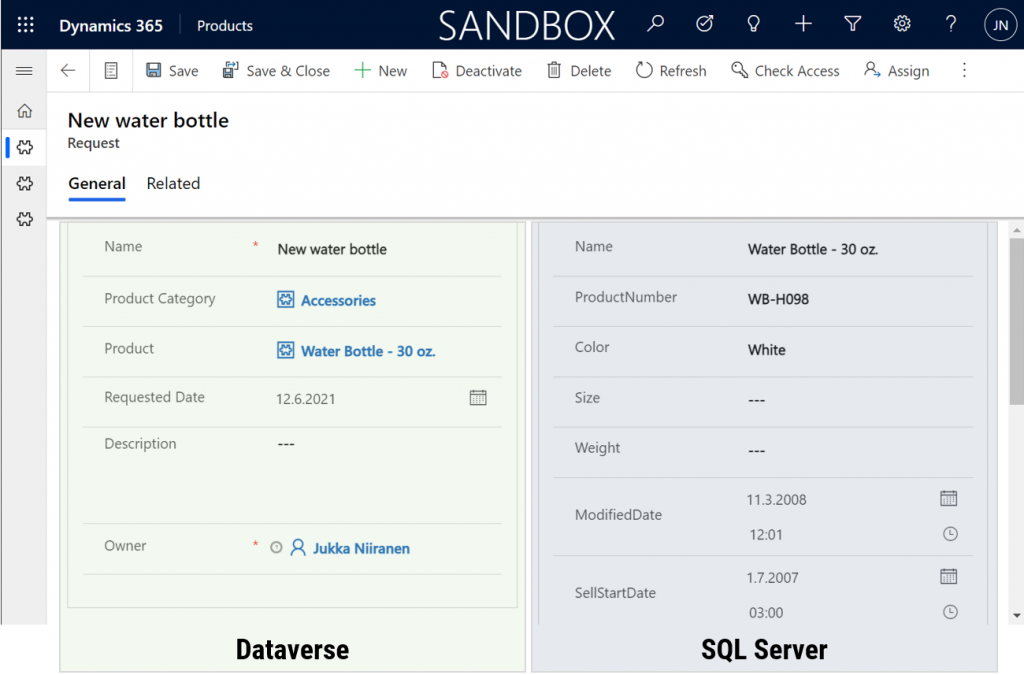
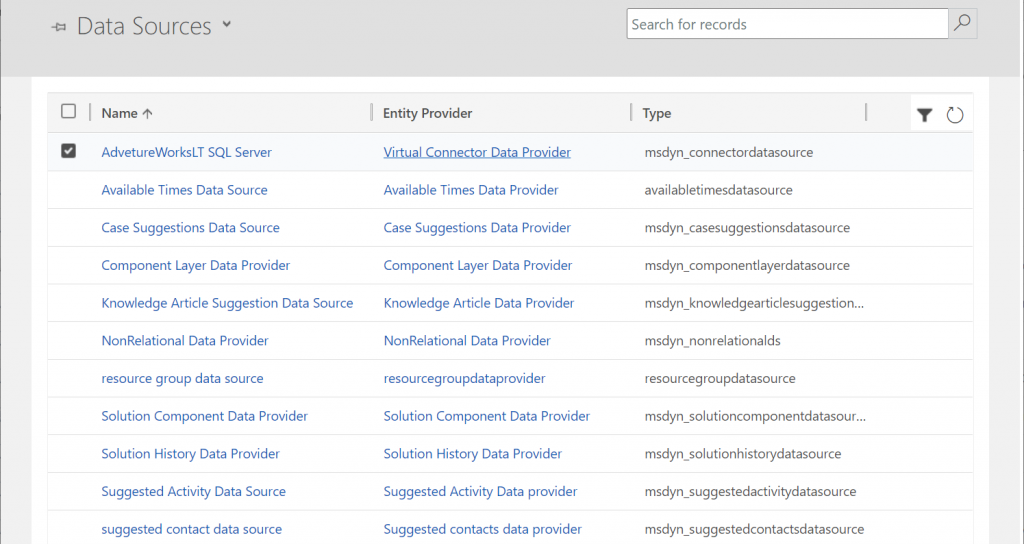

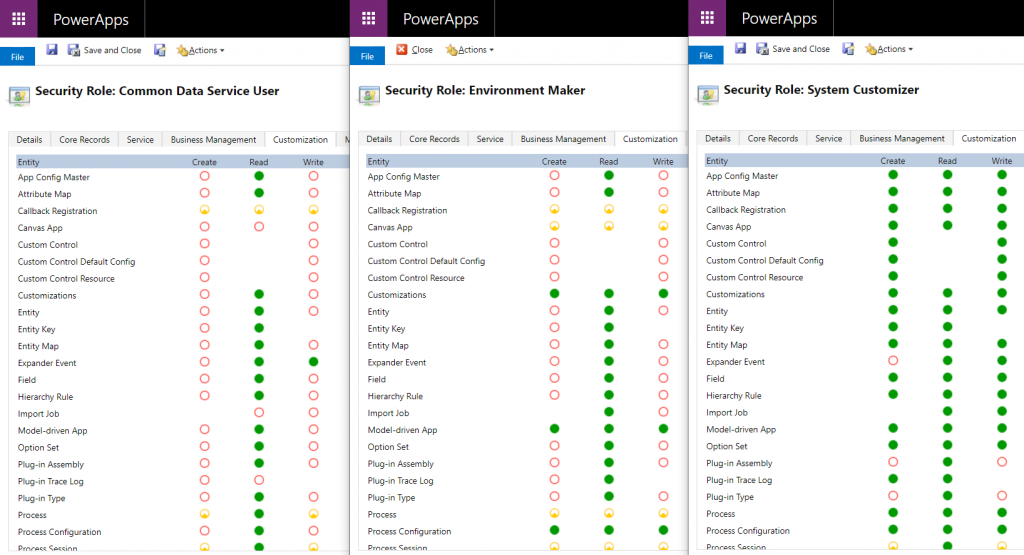









 Since it’s quite a common phase in the lifecycle of a Dynamics CRM organization to sooner or later face a situation where you want to clean up the system from legacy data structures that no longer serve their purpose, I want to highlight a couple of tools that will help you on this journey towards a better organized CRM system.
Since it’s quite a common phase in the lifecycle of a Dynamics CRM organization to sooner or later face a situation where you want to clean up the system from legacy data structures that no longer serve their purpose, I want to highlight a couple of tools that will help you on this journey towards a better organized CRM system.


 One of the problems that you may encounter during such an import process is that there are multiple matching records for the mapping fields. If you have more than one account record called “Litware, Inc”, to for example represent different regional offices of the company, mapping the primary contact by account name won’t work. Similar problems will arise if several people have the same first and last names. Therefore it’s a good practice to always generate a unique ID for each record before importing it. You can construct the identifier field in Excel with the
One of the problems that you may encounter during such an import process is that there are multiple matching records for the mapping fields. If you have more than one account record called “Litware, Inc”, to for example represent different regional offices of the company, mapping the primary contact by account name won’t work. Similar problems will arise if several people have the same first and last names. Therefore it’s a good practice to always generate a unique ID for each record before importing it. You can construct the identifier field in Excel with the 



 One of the most common customizations almost any organization working with customers from multiple countries will want to have in their Microsoft Dynamics CRM data model is the addition of a structured list of country names, to ensure they are stored in a consistent format. Yes, by default the Country/Region fields on the account, contact and lead entities are free text fields that a user must manually fill every time. This can result in some serious issues with data quality that make it difficult to perform a common task such as searching for accounts from specific countries. The field may contain values like “United States of America”, “United States”, “USA”, “Estados Unidos de América”, not to mention different conventions for upper/lowercase letters, hyphens etc.
One of the most common customizations almost any organization working with customers from multiple countries will want to have in their Microsoft Dynamics CRM data model is the addition of a structured list of country names, to ensure they are stored in a consistent format. Yes, by default the Country/Region fields on the account, contact and lead entities are free text fields that a user must manually fill every time. This can result in some serious issues with data quality that make it difficult to perform a common task such as searching for accounts from specific countries. The field may contain values like “United States of America”, “United States”, “USA”, “Estados Unidos de América”, not to mention different conventions for upper/lowercase letters, hyphens etc.




